
有什麼
Rein Room 是什麼?— 平台 1.0 功能全覽
一個在瀏覽器裡訓練 AI Agent 的強化學習平台,免安裝、即開即用
一句話定位
Rein Room(RR)是一個純前端的強化學習教育平台:你只需要開啟瀏覽器,就能讓一個 AI Agent 從零開始學習玩遊戲——看它一開始亂試、撞牆、失敗,再看它逐漸找到策略、穩定得分。 整個過程不需要安裝任何軟體、不需要寫一行程式碼,所有計算都在你的電腦本地執行。
平台網址:
reinroom.leaflune.org
— 直接開啟即可使用,免登入、免安裝。
核心功能概覽
| 功能類別 | 具體內容 |
|---|---|
| 演算法 | Q-Learning(Q-Table 離散化)、Q-Table 蒸餾式 DQN(神經網路,TensorFlow.js) |
| 遊戲環境 | 5 個內建遊戲,從最簡單的多臂拉霸到物理模擬的 CartPole,難度梯度分明 |
| 訓練視覺化 | 即時 Reward 折線圖、Steps 柱狀圖、Q-Table 熱力圖、動作分布圖、動作熱圖 |
| 超參數調整 | 學習率(α)、折扣因子(γ)、探索率(ε)可即時修改,調完立刻看效果 |
| 訓練控制 | 暫停 / 繼續、加速模式、清空記憶重新訓練、匯入 / 匯出 Q-Table |
介面布局說明
RR 的主介面分為左右兩個區域:
左
遊戲畫面區
以 iframe 嵌入的遊戲環境,你可以即時觀察 Agent 正在做什麼。 每一步動作、每一次碰壁、每一個得分都在這裡發生。
以 iframe 嵌入的遊戲環境,你可以即時觀察 Agent 正在做什麼。 每一步動作、每一次碰壁、每一個得分都在這裡發生。
右
控制面板與圖表區
上方是遊戲選擇、演算法切換、超參數設定與訓練控制按鈕; 下方是即時更新的訓練圖表,包含 Reward 曲線、Steps 趨勢、Q-Table 熱力圖等。
上方是遊戲選擇、演算法切換、超參數設定與訓練控制按鈕; 下方是即時更新的訓練圖表,包含 Reward 曲線、Steps 趨勢、Q-Table 熱力圖等。
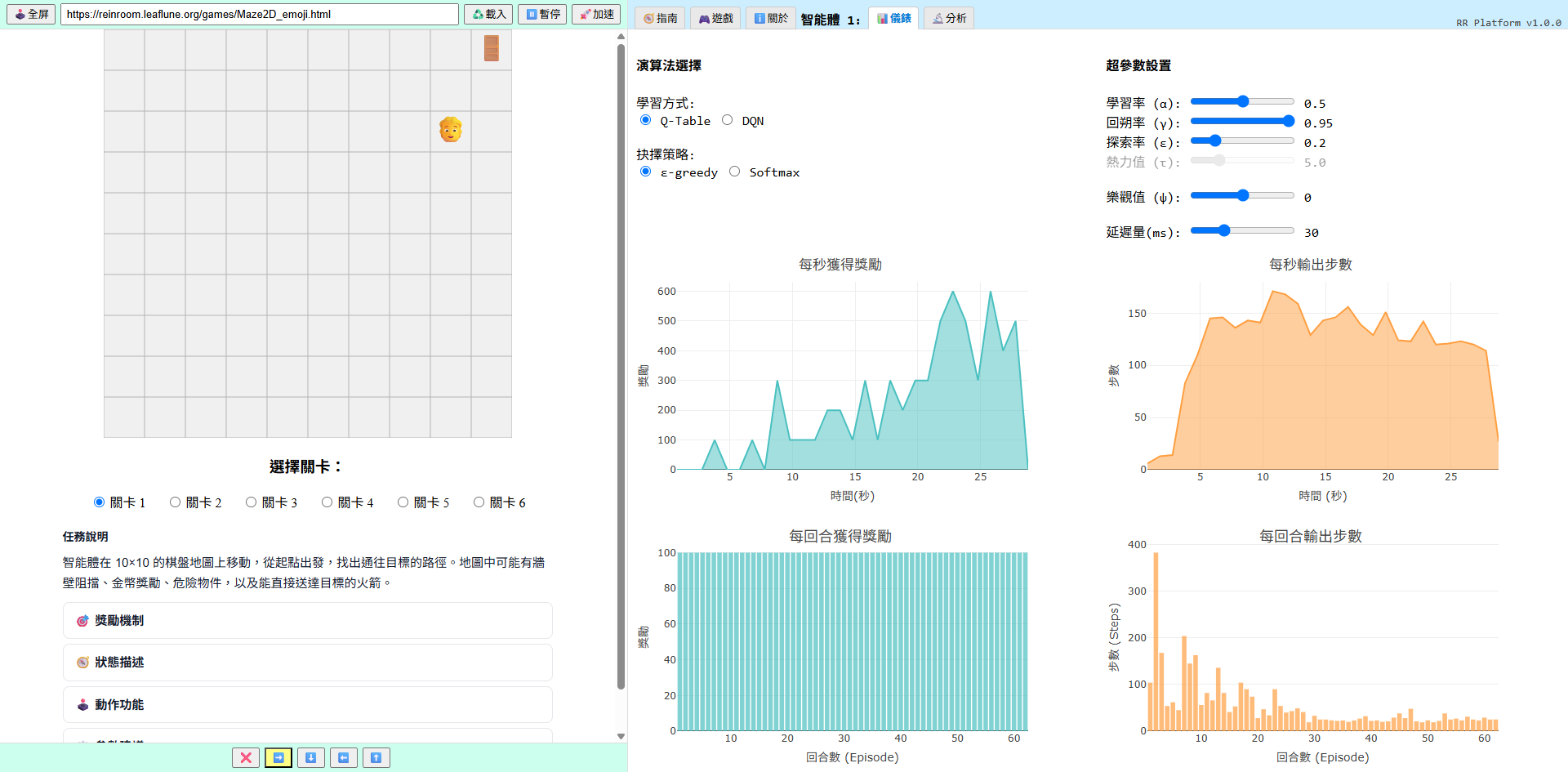
Rein Room 平台介面:左側遊戲區、右側控制面板與訓練圖表
五個遊戲環境
| 遊戲 | 簡介 | 適合學習主題 |
|---|---|---|
| 多臂拉霸(MAB) | 最簡單的情境:Agent 只能選哪台機器拉,沒有狀態轉移,純粹是探索 vs 利用的取捨。 | ε-greedy、探索策略入門 |
| 一維迷宮(Maze1D) | Agent 在一條直線上向左或向右走,找到出口即結束回合。 | Q-Table 基礎、狀態-動作映射 |
| 二維迷宮(Maze2D) | 格狀地圖上的迷宮導航,以 emoji 顯示地圖,狀態空間明顯增大。 | 狀態空間維度感、Q-Table 熱力圖解讀 |
| 直升機(heli) | 即時制飛行遊戲,Agent 要連續控制直升機上下飛行穿越障礙。 | 連續動作時序、即時制 vs 回合制 |
| CartPole | 經典物理模擬:在移動小車上保持桿子不倒,4 維連續狀態空間(位置、速度、角度、角速度)。 | 連續狀態離散化、DQN 的必要性 |
難度梯度設計:
從 MAB → Maze1D → Maze2D → heli → CartPole,狀態空間和決策複雜度逐步遞增,
適合課程循序引導,也讓學生自然感受到「為什麼需要 DQN」。
跟傳統 RL 工具的差異
傳統工具(如 OpenAI Gym)
- 需要安裝 Python 環境
- 需要撰寫訓練程式碼
- 數值輸出,可視化需額外處理
- 適合已有程式基礎的學習者
- 彈性高,可深度客製化
Rein Room
- 開啟瀏覽器即可使用
- 不需要寫程式
- 訓練過程即時視覺化
- 適合教學與初學者
- 聚焦在概念理解與觀察
RR 不是要取代 Gym,而是填補了一個缺口: 讓沒有程式背景的學生,或剛接觸 RL 的學習者, 能先建立直觀和概念,再決定是否要深入實作。
適合誰用?
1
教師與講師
想在課堂上展示 RL 概念,不想花半節課安裝環境。RR 可以直接投影,邊操作邊解說。
想在課堂上展示 RL 概念,不想花半節課安裝環境。RR 可以直接投影,邊操作邊解說。
2
學生與自學者
想理解 Q-Learning 是怎麼運作的,不只是背公式。RR 讓你看到 Q-Table 如何更新、 策略如何從隨機逐漸收斂。
想理解 Q-Learning 是怎麼運作的,不只是背公式。RR 讓你看到 Q-Table 如何更新、 策略如何從隨機逐漸收斂。
3
對 AI 感興趣的任何人
不需要數學背景,只需要好奇心。看著 Agent 慢慢學會,本身就是一件有趣的事。
不需要數學背景,只需要好奇心。看著 Agent 慢慢學會,本身就是一件有趣的事。
準備好了嗎?
打開 reinroom.leaflune.org,
選一個遊戲,按下開始,看看 Agent 需要多少回合才能學會——這是最好的入門方式。