Q-Learning — 決策價值怎麼學起來的
Q-Table 是什麼?
Q-Learning 的核心是一張叫做 Q-Table 的表格。 它的列是「狀態(State)」,行是「動作(Action)」, 每個格子裡存的數值叫做 Q 值(Q-value), 代表:「在這個狀態下,選這個動作,預期能獲得的未來總獎勵是多少?」
訓練一開始,所有 Q 值都是 0(一無所知)。 Agent 每與環境互動一步,就根據收到的 reward 更新對應格子的數值。 隨著訓練回合累積,表格逐漸反映出哪些(狀態, 動作)組合是好的、哪些是差的。
直觀比喻:像一本「路線筆記」
想像你剛搬到一個陌生城市,要從家走到公司。 一開始你完全不知道哪條路快、哪條路塞車。 你只能試著走,每天記下「從這個路口往左轉,今天花了 20 分鐘,不錯」、 「從那個巷子直走,被堵了 40 分鐘,下次不走了」。
Q-Table 就是這本「路線筆記」。Agent 每走一步,就更新一格。 走了夠多回之後,哪條路最快,筆記裡就一目瞭然—— 那就是 Q-Learning 找到最佳策略的過程。
Bellman 更新公式
每次 Agent 從狀態 s 採取動作 a、抵達新狀態 s' 並收到 reward r 時,Q-Table 就依下列公式更新:
用白話說:新 Q 值 = 舊 Q 值 + 學習率 × (新資訊 - 舊估計)。 括號裡的「新資訊」就是「這次實際拿到的 reward 加上打折後的未來最大值」, 用它和舊估計的差距,去修正 Q-Table 中對應格子的數值。
三個關鍵參數
每次更新,要信多少新資訊?
- α 高(如 0.9):學得快,但容易在剛找到的好策略上劇烈震盪,不穩定。
- α 低(如 0.1):學得慢,但更新溫和、收斂更穩。
- 一般從 0.1–0.5 開始調。
Agent 多在乎未來的獎勵?
- γ 高(如 0.99):重視長遠回報,適合需要多步規劃的任務(如 CartPole)。
- γ 低(如 0.5):只看眼前,適合短回合或即時 reward 明確的任務(如 MAB)。
控制 Q-Learning 的更新風格,範圍 -1 到 1:
- ψ = 0:標準 Q-Learning,使用下一狀態的最大 Q 值(max Q(s′, a′))。
- ψ > 0(樂觀):偏向 max,鼓勵探索未知潛力;訓練初期能加速找到好路徑。
- ψ < 0(保守,SARSA 風格):偏向實際執行的動作之 Q 值,保守穩健,適合容易失敗的環境。
Q-Table 在 RR 的視覺化:熱力圖怎麼讀
RR 提供 Q-Table 熱力圖,讓你直接看到學習進度。 熱力圖的橫軸是動作(Action),縱軸是狀態(State), 每個格子的顏色深淺代表 Q 值高低:
- 顏色越深(越暖色):Q 值越高,Agent 越「偏好」這個(狀態, 動作)組合。
- 顏色越淺(越冷色):Q 值低或尚未探索,Agent 認為這組合不佳或還不了解。
- 訓練初期,整張圖均勻淺色(一無所知);隨訓練推進,某些格子會開始突出,代表策略正在形成。
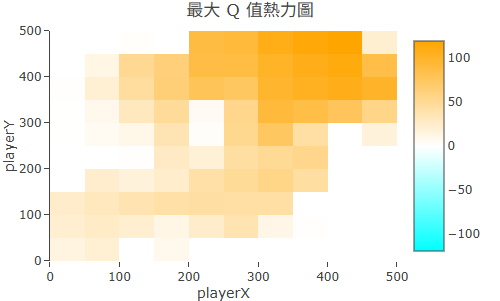
收斂後的 Q-Table:終點右上角附近 Q 值最高(橘色區域),路徑上形成漸層
搭配「動作分布圖」可以看出在某個狀態下,Agent 選各動作的頻率; 搭配「動作熱圖」(地圖上的箭頭)可以看出每個位置的最佳策略方向。
Q-Learning 的限制:Q-Table 爆炸問題
Q-Table 的格子數 = 狀態數 × 動作數。 對於簡單遊戲(如 Maze1D,10 個狀態 × 2 個動作 = 20 格),完全沒問題。 但當狀態空間變複雜,格子數會爆炸性增長:
| 遊戲 | 狀態維度 | Q-Table 格子數(估計) |
|---|---|---|
| MAB | 1 維(哪台機器) | 數十格 |
| Maze2D | 2 維(x, y 座標) | 數百格 |
| CartPole | 4 維(位置、速度、角度、角速度) | 數萬~數十萬格 |
CartPole 的 4 維連續狀態空間,即使經過離散化(每維切 10 格), 也有 10⁴ = 10,000 個狀態格。而且大多數格子很少被探索到,學習效率極差。